

The current buzzword used with quant investing is “machine learning.” Many quants may like to appear more intelligent by peppering their strategy discussions with comments like, “We use machine learning to create new and enhance our existing models.” Yet many investors don’t fully appreciate that machine learning is a term that refers to a broad set of approaches to data analysis. Many of these techniques have been around for decades. Machine learning can be an all-encompassing term.
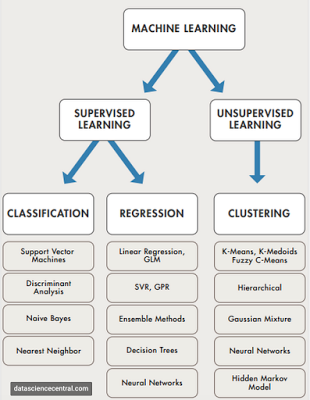
The split between supervised and unsupervised learning is at the top of the machine learning taxonomy. Supervised learning is what is done in most cases where a function is inferred from data input to a specific output. It involves training input data to reach a target outcome. Unsupervised learning is associated with searching and grouping input data to find relationships even without particular target output. Within supervised learning, there is a breakdown between the classifying events and the regression or mapping of sensitivities between input and outputs. Unsupervised learning can be defined as searching for clusters or similarities within a data set.
The real issue is understanding how managers go about their data analysis and which techniques they employ to tease out information on market behavior. How are they trying to classify data to find signals on return? How are they using regression to forecast or fit valuations to fundamentals? Or how are they searching data without a specific relationship model in place? Do they use the proper technique for the right problem? Will a different approach provide new insight into the same data? Investors have to ask why a specific plan will provide more valuable results.
The critical use of a broader set of machine learning techniques is to open up or restructure data sets to find new relationships and patterns that are not immediately obvious through linear regression, traditional time series, or simple rules. For example, decision trees and categorical analysis may help find non-linear relationships that may not immediately appear in trends or regression.
New recurring price patterns may be found due to inexpensive computing power, large data sets, and new statistical techniques. But, of course, the flip side to these atheoretical approaches is that data mining is done to excess without regard to sampling bias or the power of the tests. This is why digging into the details of what a manager may mean by machine learning is so critical. If a manager cannot effectively explain the value of their techniques to an investor, then it is not likely that these tools will do their job.
Photo by Pietro Jeng on Unsplash